
🎓 I am 21 years old and currently pursuing an MSc in Computer Science (Global Transfer Programme) at the University of Bristol.
🧪 My research centers on reliable multimodal intelligence: building and evaluating Multimodal Large Language Models (MLLMs) that can reason consistently, reduce hallucinations, and quantify uncertainty under challenging or missing visual evidence.
⚙️ Methodologically, I work on efficient adaptation and deployment (e.g., PEFT), as well as continual / long-horizon learning for systems that remain robust as tasks, context, and data distributions evolve.
🌍 I aim to advance trustworthy AI that is not only powerful, but also transparent and useful—so that progress in AI translates into meaningful social impact.
Honors & Awards
-
🏅️Kaggle Gold Medal, Home Credit - Credit Risk Model Stability (Top 9 / 3856 Teams)2024
-
🥈Kaggle Silver Medal, LMSYS - Chatbot Arena Human Preference Predictions (Top 90 / 1849 Teams)2023
-
🎓 University of Bristol THINK BIG Scholarship (£9,500)2025
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "News
Selected Publications (view all )

CATP: Contextually Adaptive Token Pruning for Efficient and Enhanced Multimodal In-Context Learning
Yanshu Li* (co-first author), Jianjiang Yang* (co-first author), Zhennan Shen, Ligong Han, Haoyan Xu, Ruixiang Tang
AAAI 2026 Oral (accepted) 2026
Modern large vision-language models (LVLMs) convert each input image into a large set of tokens, far outnumbering the text tokens. Although this improves visual perception, it introduces severe image token redundancy. Because image tokens carry sparse information, many add little to reasoning, yet greatly increase inference cost. The emerging image token pruning methods tackle this issue by identifying the most important tokens and discarding the rest. These methods can raise efficiency with only modest performance loss. However, most of them only consider single-image tasks and overlook multimodal in-context learning (ICL), where redundancy is greater and efficiency is more critical. Redundant tokens weaken the advantage of multimodal ICL for rapid domain adaptation and cause unstable performance. Applying existing pruning methods in this setting leads to large accuracy drops, exposing a clear gap and the need for new techniques. Thus, we propose Contextually Adaptive Token Pruning (CATP), a training-free pruning method targeted at multimodal ICL. CATP consists of two stages that perform progressive pruning to fully account for the complex cross-modal interactions in the input sequence. After removing 77.8% of the image tokens, CATP produces an average performance gain of 0.6% over the vanilla model on four LVLMs and eight benchmarks, exceeding all baselines remarkably. Meanwhile, it effectively improves efficiency by achieving an average reduction of 10.78% in inference latency. CATP enhances the practical value of multimodal ICL and lays the groundwork for future progress in interleaved image-text scenarios.
CATP: Contextually Adaptive Token Pruning for Efficient and Enhanced Multimodal In-Context Learning
Yanshu Li* (co-first author), Jianjiang Yang* (co-first author), Zhennan Shen, Ligong Han, Haoyan Xu, Ruixiang Tang
AAAI 2026 Oral (accepted) 2026
Modern large vision-language models (LVLMs) convert each input image into a large set of tokens, far outnumbering the text tokens. Although this improves visual perception, it introduces severe image token redundancy. Because image tokens carry sparse information, many add little to reasoning, yet greatly increase inference cost. The emerging image token pruning methods tackle this issue by identifying the most important tokens and discarding the rest. These methods can raise efficiency with only modest performance loss. However, most of them only consider single-image tasks and overlook multimodal in-context learning (ICL), where redundancy is greater and efficiency is more critical. Redundant tokens weaken the advantage of multimodal ICL for rapid domain adaptation and cause unstable performance. Applying existing pruning methods in this setting leads to large accuracy drops, exposing a clear gap and the need for new techniques. Thus, we propose Contextually Adaptive Token Pruning (CATP), a training-free pruning method targeted at multimodal ICL. CATP consists of two stages that perform progressive pruning to fully account for the complex cross-modal interactions in the input sequence. After removing 77.8% of the image tokens, CATP produces an average performance gain of 0.6% over the vanilla model on four LVLMs and eight benchmarks, exceeding all baselines remarkably. Meanwhile, it effectively improves efficiency by achieving an average reduction of 10.78% in inference latency. CATP enhances the practical value of multimodal ICL and lays the groundwork for future progress in interleaved image-text scenarios.
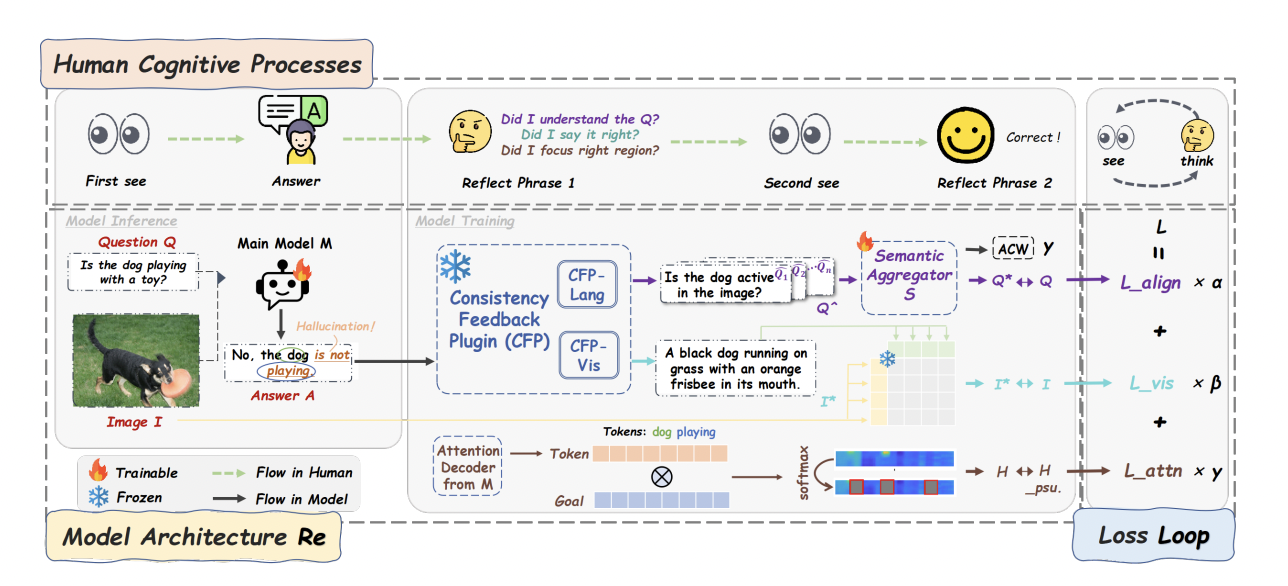
ReLoop: 'Seeing Twice and Thinking Backwards' via Closed-loop Training to Mitigate Hallucinations in Multimodal Understanding
Jianjiang Yang* (first author), Yanshu Li, Ziyan Huang
EMNLP 2025 Findings (Accepted) 2025
Multimodal Large Language Models (MLLMs) remain vulnerable to hallucinations that contradict or misrepresent input semantics. We propose "ReLoop", a closed-loop training framework that enforces cross-modal consistency via a ring-shaped structure with three complementary consistency feedback mechanisms. ReLoop encourages models to "see twice and think backwards", effectively mitigating hallucinations and improving semantic reliability in multimodal reasoning. Extensive experiments demonstrate significant improvements across multiple benchmarks.
ReLoop: 'Seeing Twice and Thinking Backwards' via Closed-loop Training to Mitigate Hallucinations in Multimodal Understanding
Jianjiang Yang* (first author), Yanshu Li, Ziyan Huang
EMNLP 2025 Findings (Accepted) 2025
Multimodal Large Language Models (MLLMs) remain vulnerable to hallucinations that contradict or misrepresent input semantics. We propose "ReLoop", a closed-loop training framework that enforces cross-modal consistency via a ring-shaped structure with three complementary consistency feedback mechanisms. ReLoop encourages models to "see twice and think backwards", effectively mitigating hallucinations and improving semantic reliability in multimodal reasoning. Extensive experiments demonstrate significant improvements across multiple benchmarks.
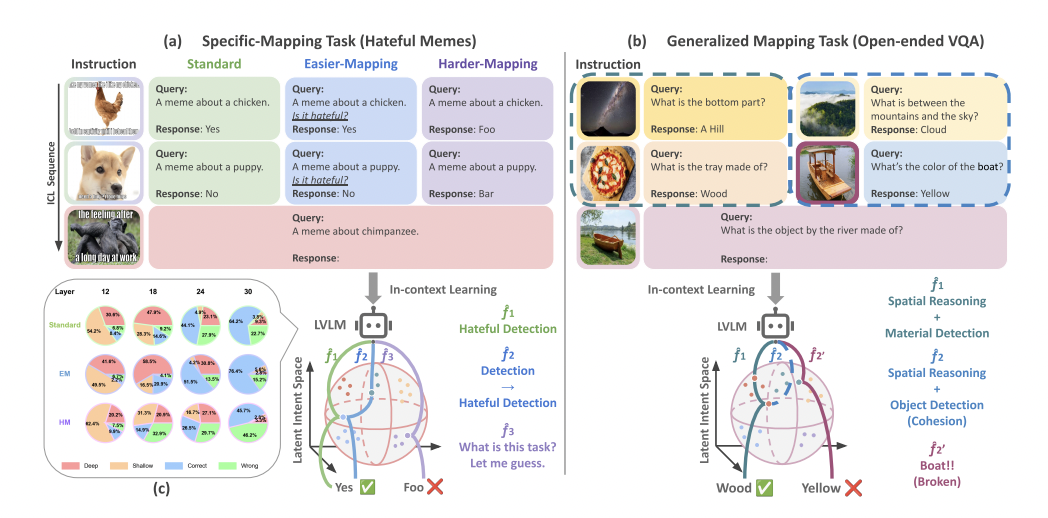
TACO: Enhancing Multimodal In-context Learning via Task Mapping-Guided Sequence Configuration
Yanshu Li, Jianjiang Yang*, Tian Yun, Pinyuan Feng, Jinfa Huang, Ruixiang Tang (* equal contribution)
EMNLP 2025 Main Conference (Accepted) 2025
Multimodal in-context learning (ICL) has emerged as a key mechanism for harnessing the capabilities of large vision-language models (LVLMs). However, its effectiveness remains highly sensitive to the quality of input sequences. We propose "TACO", a lightweight transformer-based model guided by task mapping, which dynamically configures in-context sequences via task-aware attention. TACO enables a bidirectional synergy between sequence construction and task reasoning, consistently surpassing baselines on five LVLMs and nine benchmarks. These results highlight task mapping as a valuable perspective for improving multimodal ICL.
TACO: Enhancing Multimodal In-context Learning via Task Mapping-Guided Sequence Configuration
Yanshu Li, Jianjiang Yang*, Tian Yun, Pinyuan Feng, Jinfa Huang, Ruixiang Tang (* equal contribution)
EMNLP 2025 Main Conference (Accepted) 2025
Multimodal in-context learning (ICL) has emerged as a key mechanism for harnessing the capabilities of large vision-language models (LVLMs). However, its effectiveness remains highly sensitive to the quality of input sequences. We propose "TACO", a lightweight transformer-based model guided by task mapping, which dynamically configures in-context sequences via task-aware attention. TACO enables a bidirectional synergy between sequence construction and task reasoning, consistently surpassing baselines on five LVLMs and nine benchmarks. These results highlight task mapping as a valuable perspective for improving multimodal ICL.
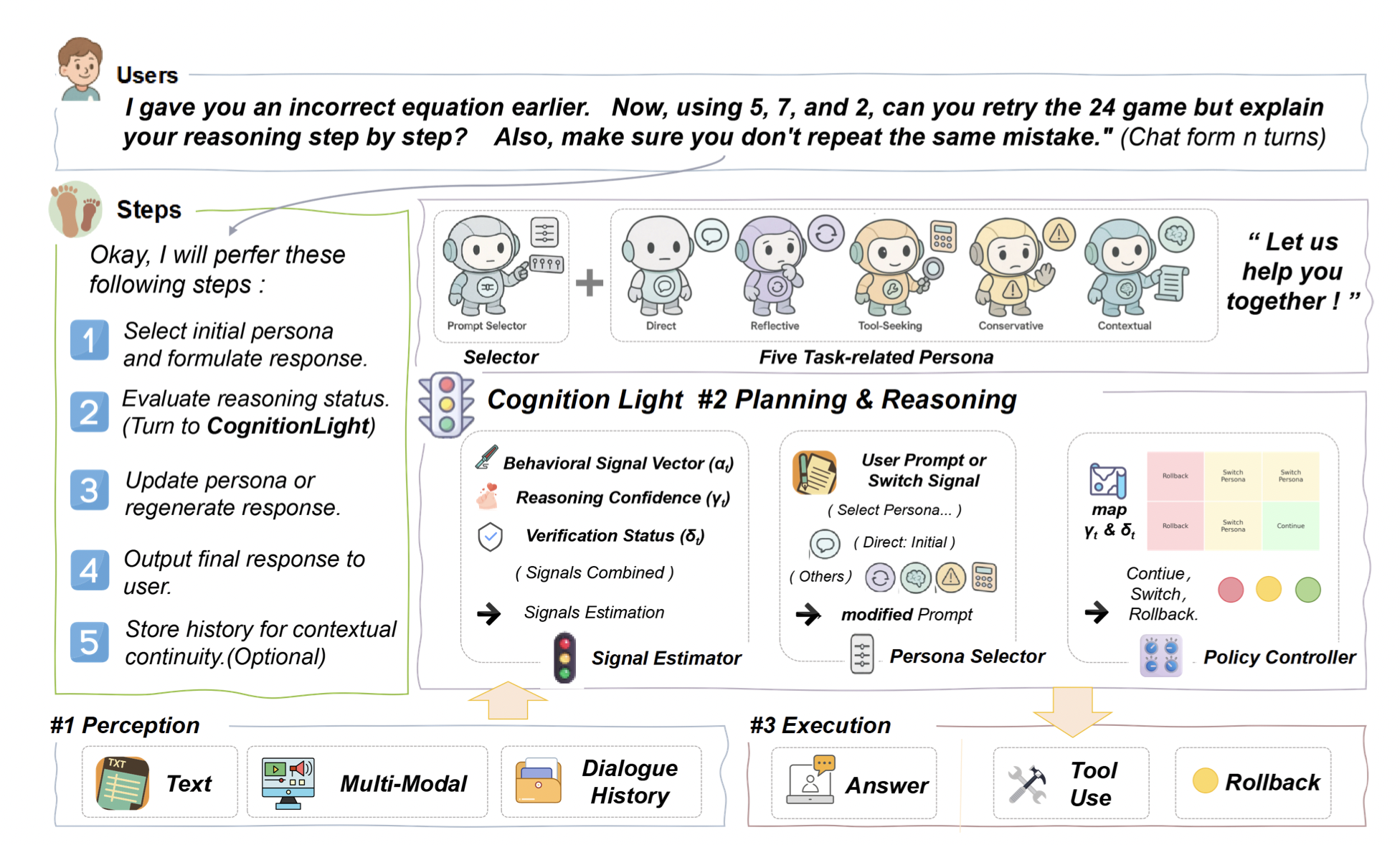
CognitionLight: Continue, Rethink, or Rollback? Signaling for Persona-Aware Reasoning in Intelligent Agents
Jianjiang Yang*, Ziyan Huang, Yanshu Li, Da Peng, Huaiyuan Yao (* equal contribution)
ICLR 2026 (Under Review) 2025
Inspired by human meta-reasoning, this work introduces "CognitionLight", a cognitively inspired control plugin that regulates agent behavior via symbolic “traffic-light” signals (Continue, Switch Persona, Rollback). CognitionLight adaptively guides reasoning strategies in multi-turn scenarios, mitigating hallucinations and enabling adaptive persona-aware reasoning. Experiments on multi-turn reasoning benchmarks show that CognitionLight improves response consistency, reduces hallucinations, and enhances flexibility in dynamic agent behavior.
CognitionLight: Continue, Rethink, or Rollback? Signaling for Persona-Aware Reasoning in Intelligent Agents
Jianjiang Yang*, Ziyan Huang, Yanshu Li, Da Peng, Huaiyuan Yao (* equal contribution)
ICLR 2026 (Under Review) 2025
Inspired by human meta-reasoning, this work introduces "CognitionLight", a cognitively inspired control plugin that regulates agent behavior via symbolic “traffic-light” signals (Continue, Switch Persona, Rollback). CognitionLight adaptively guides reasoning strategies in multi-turn scenarios, mitigating hallucinations and enabling adaptive persona-aware reasoning. Experiments on multi-turn reasoning benchmarks show that CognitionLight improves response consistency, reduces hallucinations, and enhances flexibility in dynamic agent behavior.
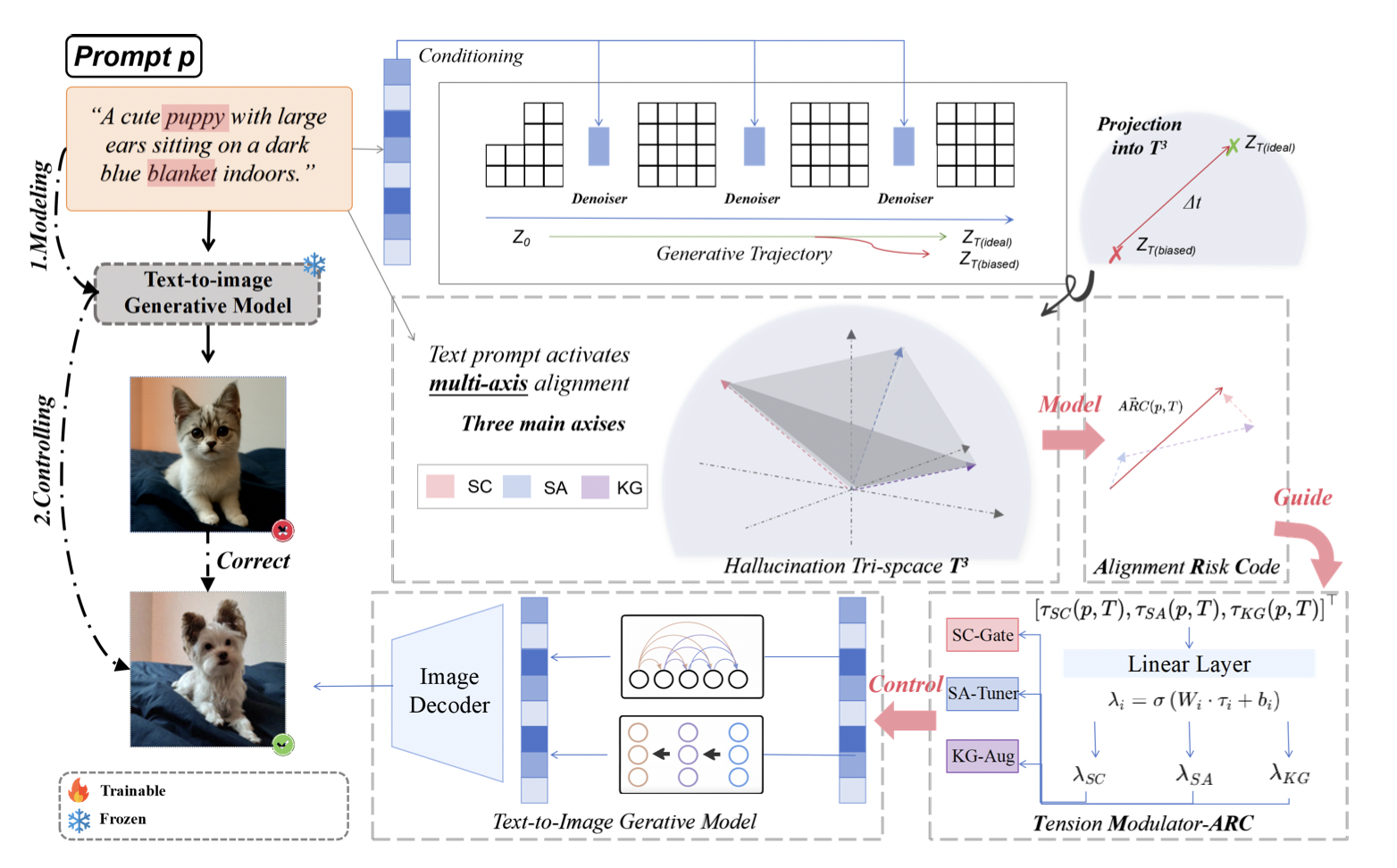
Taming the Tri-Space Tension: ARC-Guided Hallucination Modeling and Control for Text-to-Image Generation
Jianjiang Yang*, Ziyan Huang, Yanshu Li, Huaiyuan Yao, Da Peng (* equal contribution)
ICLR 2026 (Under Review) 2025
Despite remarkable progress in image quality and fidelity, text-to-image (T2I) diffusion models continue to exhibit persistent hallucinations where generated outputs subtly or significantly diverge from the intended semantics. We propose "Tri-Space Tension Modeling (TM-ARC)", which reinterprets hallucinations as trajectory drift in a latent alignment space. By quantifying semantic coherence, structural alignment, and knowledge grounding via a dynamic Alignment Risk Code (ARC), TM-ARC identifies dominant failure axes and applies targeted, axis-specific interventions. This framework reduces hallucination without sacrificing diversity or fidelity, providing a unified and interpretable approach for controllable text-to-image generation.
Taming the Tri-Space Tension: ARC-Guided Hallucination Modeling and Control for Text-to-Image Generation
Jianjiang Yang*, Ziyan Huang, Yanshu Li, Huaiyuan Yao, Da Peng (* equal contribution)
ICLR 2026 (Under Review) 2025
Despite remarkable progress in image quality and fidelity, text-to-image (T2I) diffusion models continue to exhibit persistent hallucinations where generated outputs subtly or significantly diverge from the intended semantics. We propose "Tri-Space Tension Modeling (TM-ARC)", which reinterprets hallucinations as trajectory drift in a latent alignment space. By quantifying semantic coherence, structural alignment, and knowledge grounding via a dynamic Alignment Risk Code (ARC), TM-ARC identifies dominant failure axes and applies targeted, axis-specific interventions. This framework reduces hallucination without sacrificing diversity or fidelity, providing a unified and interpretable approach for controllable text-to-image generation.

CAMA: Enhancing Multimodal In-Context Learning with Context-Aware Modulated Attention
Yanshu Li, Jianjiang Yang*, Ziteng Yang, Bozheng Li, Hongyang He, Zhengtao Yao, Ligong Han, Yingjie Victor Chen, Songlin Fei, Dongfang Liu, Ruixiang Tang (* equal contribution)
AAAI 2026 Oral (accepted) 2026
Multimodal in-context learning (ICL) is emerging as a key capability that enables large vision-language models (LVLMs) to adapt to novel tasks without parameter updates, expanding their utility across various real-world applications. However, ICL remains unstable, even with well-matched in-context demonstrations (ICDs), suggesting that LVLMs struggle to fully utilize the provided context. While existing efforts focus on prompt engineering or post-hoc logit calibration, we instead investigate the underlying attention dynamics to overcome LVLMs' inherent limitations. To bridge the gap, we propose Context-Aware Modulated Attention (CAMA), a plug-and-play and training-free method that dynamically modulates LVLM's attention logits based on the input in-context sequence. CAMA employs a two-stage attention modulation to address both identified deficits, enhancing the focus on semantically significant tokens, particularly visual ones. Across four LVLMs and seven benchmarks, CAMA consistently outperforms vanilla models and baselines, demonstrating great effectiveness and generalization. It can also activate the desired effects of prompt engineering methods and remains robust under diverse sequence configurations. Thus, CAMA paves the way for deeper explorations of attention dynamics to advance multimodal reasoning.
CAMA: Enhancing Multimodal In-Context Learning with Context-Aware Modulated Attention
Yanshu Li, Jianjiang Yang*, Ziteng Yang, Bozheng Li, Hongyang He, Zhengtao Yao, Ligong Han, Yingjie Victor Chen, Songlin Fei, Dongfang Liu, Ruixiang Tang (* equal contribution)
AAAI 2026 Oral (accepted) 2026
Multimodal in-context learning (ICL) is emerging as a key capability that enables large vision-language models (LVLMs) to adapt to novel tasks without parameter updates, expanding their utility across various real-world applications. However, ICL remains unstable, even with well-matched in-context demonstrations (ICDs), suggesting that LVLMs struggle to fully utilize the provided context. While existing efforts focus on prompt engineering or post-hoc logit calibration, we instead investigate the underlying attention dynamics to overcome LVLMs' inherent limitations. To bridge the gap, we propose Context-Aware Modulated Attention (CAMA), a plug-and-play and training-free method that dynamically modulates LVLM's attention logits based on the input in-context sequence. CAMA employs a two-stage attention modulation to address both identified deficits, enhancing the focus on semantically significant tokens, particularly visual ones. Across four LVLMs and seven benchmarks, CAMA consistently outperforms vanilla models and baselines, demonstrating great effectiveness and generalization. It can also activate the desired effects of prompt engineering methods and remains robust under diverse sequence configurations. Thus, CAMA paves the way for deeper explorations of attention dynamics to advance multimodal reasoning.
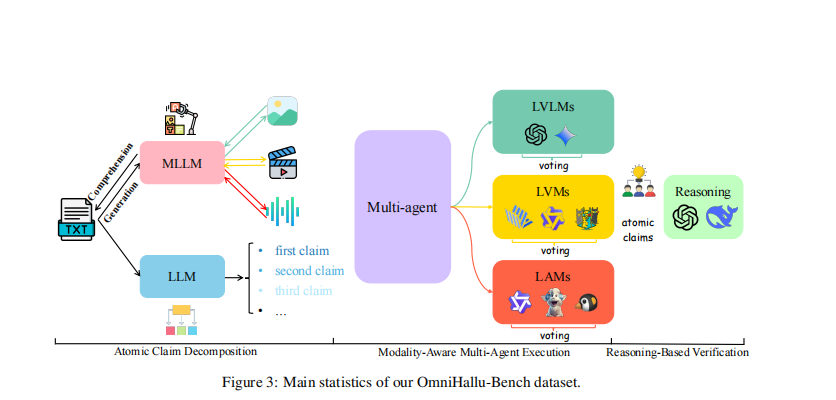
OmniHallu: Unified Hallucination Detection for Cross-Modal Comprehension and Generation in Multimodal Large Language Models
Jianjiang Yang (First Author), Peihang Li, Yanxiang Huang, Shanqing Xu, Lu Zhang, Junhao Dong, Dong Huang, Meng Luo
Preparing for ACL 2026 Submission 2026
Multimodal Large Language Models (MLLMs) have made significant progress but remain prone to hallucinations that contradict input semantics. We introduce **OmniHallu**, a unified hallucination detection and evaluation framework designed to generalize across both comprehension and generation tasks, spanning text, image, video, and audio modalities. OmniHallu integrates **OmniHallu-Bench**, a large-scale benchmark for cross-modal hallucination analysis, and a **multi-agent verification architecture** that decomposes and validates multimodal reasoning chains. Extensive experiments demonstrate the framework’s superior interpretability, generalization, and robustness, paving the way for trustworthy multimodal intelligence.
OmniHallu: Unified Hallucination Detection for Cross-Modal Comprehension and Generation in Multimodal Large Language Models
Jianjiang Yang (First Author), Peihang Li, Yanxiang Huang, Shanqing Xu, Lu Zhang, Junhao Dong, Dong Huang, Meng Luo
Preparing for ACL 2026 Submission 2026
Multimodal Large Language Models (MLLMs) have made significant progress but remain prone to hallucinations that contradict input semantics. We introduce **OmniHallu**, a unified hallucination detection and evaluation framework designed to generalize across both comprehension and generation tasks, spanning text, image, video, and audio modalities. OmniHallu integrates **OmniHallu-Bench**, a large-scale benchmark for cross-modal hallucination analysis, and a **multi-agent verification architecture** that decomposes and validates multimodal reasoning chains. Extensive experiments demonstrate the framework’s superior interpretability, generalization, and robustness, paving the way for trustworthy multimodal intelligence.
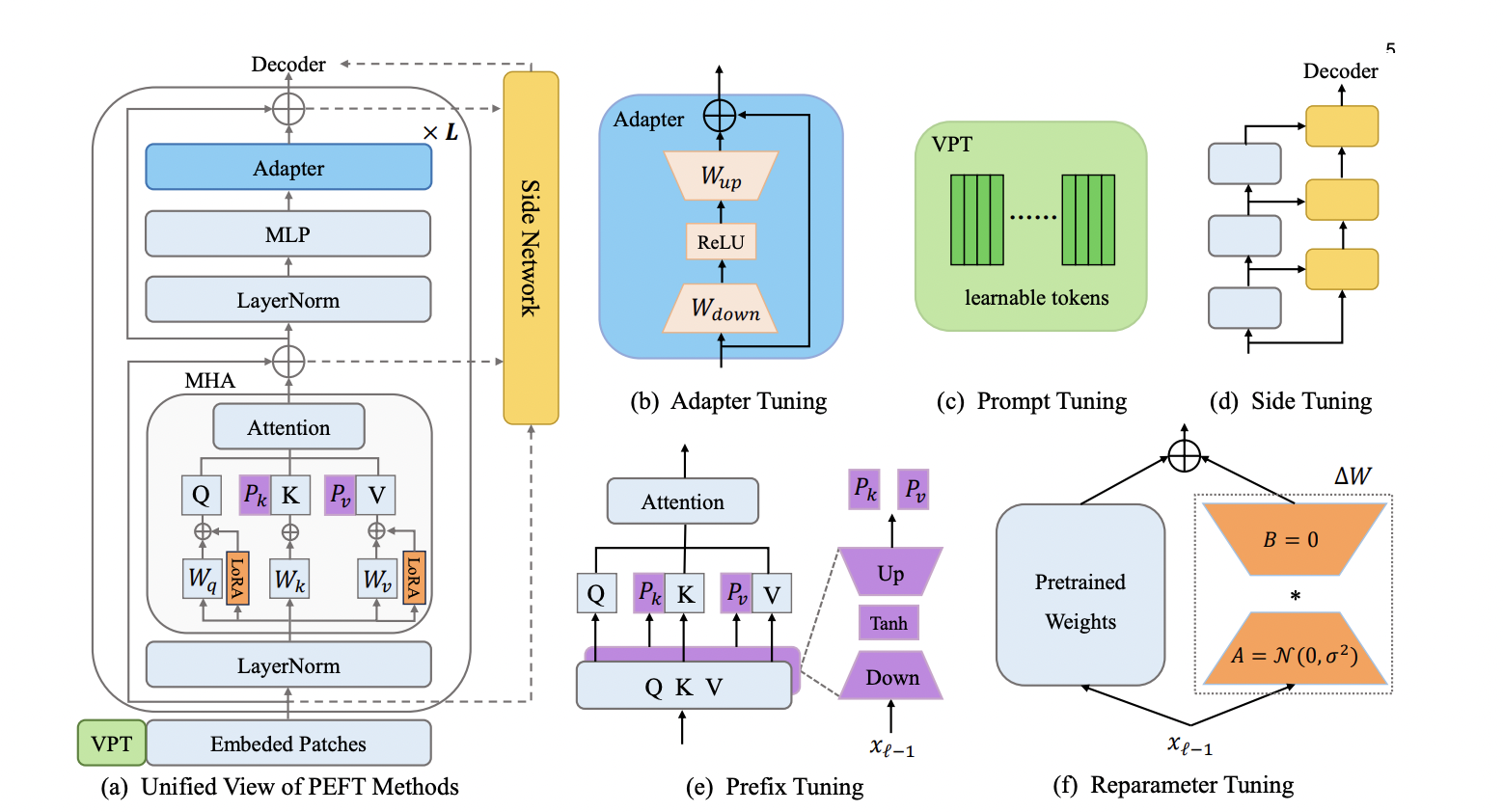
Parameter-Efficient Fine-Tuning for Pre-Trained Vision Models: A Survey and Benchmark
Yi Xin (co-first author), Jianjiang Yang* (co-first author), Siqi Luo, Yuntao Du, Qi Qin, Kangrui Cen, Yangfan He, Bin Fu, Xiaokang Yang, Guangtao Zhai, Ming-Hsuan Yang, Xiaohong Liu
IEEE @ TPAMI (under review) 2024
This paper presents a comprehensive survey of the latest advancements in parameter-efficient fine-tuning (PEFT) for pre-trained vision models, systematically reviewing methodologies and introducing the V-PEFT Bench benchmark. We categorize existing approaches into addition-based, partial-based, unified-based, and multi-task tuning, and provide insights into widely used datasets and applications. The survey has already received "130+ citations" and the associated GitHub repository has earned "570+ stars", highlighting its significant impact in both academia and practice.
Parameter-Efficient Fine-Tuning for Pre-Trained Vision Models: A Survey and Benchmark
Yi Xin (co-first author), Jianjiang Yang* (co-first author), Siqi Luo, Yuntao Du, Qi Qin, Kangrui Cen, Yangfan He, Bin Fu, Xiaokang Yang, Guangtao Zhai, Ming-Hsuan Yang, Xiaohong Liu
IEEE @ TPAMI (under review) 2024
This paper presents a comprehensive survey of the latest advancements in parameter-efficient fine-tuning (PEFT) for pre-trained vision models, systematically reviewing methodologies and introducing the V-PEFT Bench benchmark. We categorize existing approaches into addition-based, partial-based, unified-based, and multi-task tuning, and provide insights into widely used datasets and applications. The survey has already received "130+ citations" and the associated GitHub repository has earned "570+ stars", highlighting its significant impact in both academia and practice.